Milking GPTs Until... What?
August 2025 (1713 Words, 10 Minutes)
Mood: Curious
For about a year and a half I’ve been working a bit of a freelance side-gig that involves scoring, editing, and annotating data to help train large language models (LLMs). I took the opportunity originally for the simple reason to bring in a bit more cash, and the platform I work for was ready to pay $40/hr for coding work. It has been a great blessing to our family, and to be honest I should probably be taking more advantage of the opportunity while it lasts.
You may be thinking I hopped on a train to teach bots how to take my job. They’re becoming incredibly powerful, yes, but the existential threat to our way of life may not be what you think. After 18 months of carefully assessing the quality of model-generated responses to hundreds of different questions, I can tell you two things: (1) they are getting really good at pretty much everything that can be learned through sheer absorption of knowledge and computational implementation, and (2) they won’t be taking your (or my) job anytime soon unless you don’t adapt to the emerging tech and learn to work alongside these tools. They are in no way generally intelligent entities, and if anything you should just become more effective at what you currently do with them at your fingertips.

At the end of the day, that’s what these models are: tools to synthesize massive amounts of content to produce more content that is linguistically-structured at its core. Programming, summarization of text, parsing of PDFs to extract insight and metrics, learning how to arrange pixels on a screen to produce images and sequences of images (AKA videos), etc. are all fundamentally language-driven tasks. Even images when seen as patterned sequences of color values can be easily interpreted as a form of structured language.
The image below outlines the basic architecture of an early generative pre-trained (GPT) language model, the GPT-1 model. This is extremely small compared to modern models, but I would assert that newer models don’t have any fundamentally revolutionary new components in their architecture that have the ability to overcome their inability to exhibit true intelligence. More on that later.
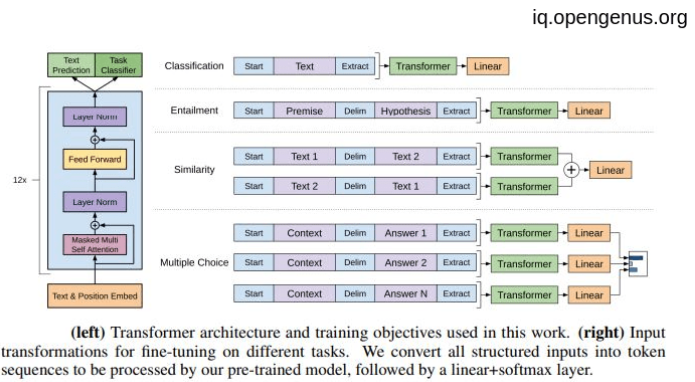
Below is a high-level breakdown of the progression of emerging models based fundamentally on this architecture. This was generated in part by OpenAI’s GPT-5, but I’ve checked its veracity where possible and fixed it enough to be correct where I could validate the figures. I checked all the links, and after making some adjustments they all work at the time of writing (yes, GPT-5 hallucinates!🤯).
| Dev | Model | Release date | Training data size | # Params | Improvements vs prev. |
|---|---|---|---|---|---|
| OpenAI | GPT-1 | Jun 2018 | ~4.5 GB | 117M | First large-scale unsup. pretrain for NLP |
| OpenAI | GPT-2 | 2019 | ~40 GB | 1.5B | Longer coherent gen., staged release |
| OpenAI | GPT-3 | Jun 2020 | ~570GB | 175B | Strong few-shot perf., 10× scale |
| OpenAI | GPT-3.5 | 2022–23 | N/A | N/A | Better instr.-following, latency |
| Google DeepMind | PaLM 2 | May 2023 | ~3.6T tokens | ~340B | Multilingual, reasoning, coding |
| Meta | Llama 2 | Jul 2023 | ~2T tokens | 7B, 13B, 70B | More data, tuned chat, open weights |
| Google DeepMind | Gemini | Dec 2023+ | N/A | N/A | Multimodal, tools, long context |
| Meta | Llama 3 | Apr 2024 | ~15T tokens | 8B, 70B, 405B | Bigger scale, longer ctx, multimodal |
| OpenAI | GPT-4o | May 2024 | N/A | N/A | Real-time multimodal, faster/cheaper |
| Anthropic | Claude 3 | Mar 2024 | N/A | N/A | Family split, large ctx, better reasoning |
| Anthropic | Claude 3.5 Sonnet | Jun 2024 | N/A | N/A | Faster, higher benchmarks |
| Google DeepMind | Gemini 2.5 Flash | 2024–25 | N/A | N/A | Faster, 1M ctx, tool use |
| Google DeepMind | Gemini 2.5 Pro | 2024–25 | N/A | N/A | Higher-capability multimodal |
| Meta | Llama 4 | Apr 2025 | >30T tokens | MoE: 17B active, up to ~400B total | MoE arch., multimodal, long ctx |
| Anthropic | Claude Sonnet 4 | May 2025 | N/A | N/A | Hybrid reasoning, better coding/math |
| OpenAI | GPT-5 | Aug 2025 | N/A | N/A | Unified reasoning, better coding/math |
| Anthropic | Claude Opus 4.1 | Aug 2025 | N/A | N/A | Better coding, agentic precision |
In general, these models have become more useful and “better” due to a few key areas of improvement.
More Knowledge and Larger Parameter Sets
GPT-1 was trained on a corpus of about 7,000 texts/books that likely added up to be in the realm of 6-10GB of total training data. That’s a lot of books, but consider this: GPT-2, which is now nearly 6 years old, was trained on around 40GB of text data! GPT-3, which is now about 5 years old was trained on a dataset that initially consisted of 45TB of text data, that was distilled down to about 570GB after deduplication and other filtering mechanisms.
Similarly, the parameter space these models are exploring is astronomically large. Scaling tenfold from GPT-1 to 2 to 3, each, it is posited by some that GPT-4 consists of anywhere between 1.5 to 2.0 Trillion model parameters, suggesting training data on the order of 20+ TB - but at this point we’re just speculating. The take-home is that extremely new models like Claude Opus 4.1 and GPT-5 are barely fathomably large - probably on the order of 10-20 Trillion model parameters and 20x that in bytes of training data. Their knowledge base is essentially equal to that of all the unique text passages in the accessible internet.
Instruction-Tuning & Reinforcement Learning from Human Feedback (RLHF)
RLHF is a state-of-the-art mechanism for curating training data for language models and other generative tools to mechanistically reward models for producing responses that are similar to actual human responses to prompts provided by real humans. This is essentially what I do for my freelance gig - I write a prompt, the model provides two responses, and I rate/score the responses based on various axes of quality and sometimes even edit the responses to “teach” the model how the correct answer should look and why/how it’s different from the one it gave.
Multi-Modal Capabilities
All this means is that instead of strictly being good at producing reasonable language responses, the model construction also provides image, video, or audio generation capabilities. Essentially this becomes possible as the parameter space for the model increases and its weights have the flexibility to produce even more types of output. Basically any top-of-line model released after 2023 has this capability.
Expanded Context Window
Novel approaches to attention mechanisms, scaled-up hardware, and other efficiency gains in model architecture now allow for huge context windows compared to early models. Whereas GPT-3 only allowed for 2048 tokens in its context window, most state-of-the-art implementations offer at least 128k-256k token context windows. Google’s Gemini 2.5 Pro released with a 1M token context window, and Meta’s Llama 4 - Scout claims to efficiently boast a 10M token context window. These improvements essentially allow for more effective long conversations and long document parsing.
Mixture-of-Experts Approach
By 2025 many of these models implemented a Mixture-of-Experts (MoE) approach, which essentially provides a mechanism to efficiently route prompt tokens through a hierarchy of model structures and generate content based on that context with potentially only a portion of the entire parent model’s parameter set. I’m not an expert on this subject, but this is how I understand it.
For example, if GPT-5 sees the prompt is to write a simple sonnet it won’t use its complete giant dense network to generate new content; instead, the routing will help the model choose a sparser lightweight parameter set pre-trained for creative writing for most of the tokens. If I asked it code up Rollercoaster Tycoon 5 in Assembly, it would route more of those tokens to a more dense, robust, model pre-trained for coding and analytical language.
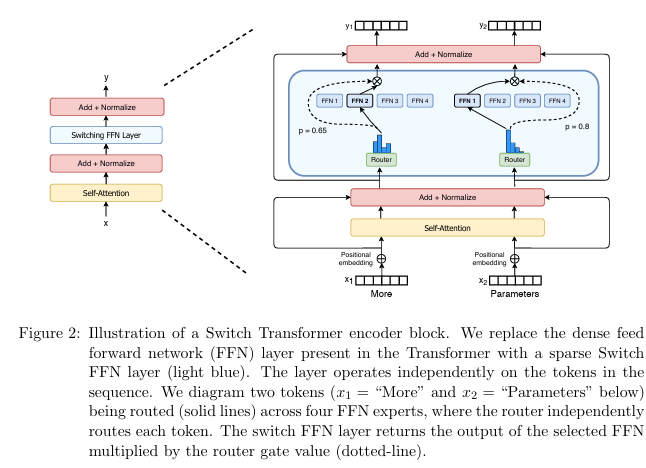
The above diagram is from a paper on efficient scaling of transformer models.
These improvements are awesome, but no LLM can properly reason through problems that are not based on huge knowledge priors. What do I mean by knowledge priors? I define knowledge as information related to a task domain. That may seem broad or confusing, but it’s purposefully very general, and excludes proper reasoning and intelligence as part of the definition.
I don’t view reasoning and intelligence as fundamentally linked to knowledge, although they certainly interoperate with each other. Intelligence is more associated with an entity’s ability to identify general patterns, acquire skills, and formulate new specific patterns and ideas without being exposed to them a priori. Reasoning is the ability to formulate logical, structured hypotheses and make justifiable inference in the presence of acquired knowledge.
My view is that the current architecture and learning mechanisms of the biggest and best AI models right now are purely leveraging massive knowledge bases and indexing them efficiently to produce reasonable and well-structured output. Specifically output that would likely have been produced by a human, or group of humans, that also has access to that knowledge base and enough time to understand it and answer the same prompt.
There have been valuable experiments and assessments made on the best models out there that indicate this view is mostly justified. The “Abstract and Reasoning Corpus” for Artificial General Intelligence (ARC-AGI) is a set of benchmark tests created by Francois Chollet and other researchers that aims to isolate reasoning and intelligence to train models. This corpus presents puzzles and tasks in a way that creates an environment nearly free of knowledge leverage. By this I mean that the puzzles strictly require fundamental pattern recognition, skill acquisition, and logic with extremely limited exposure to — or ability to take advantage of — pure knowledge. With a maximum of two attempts per task, a panel of humans was able to achieve 100% accuracy at an average cost of $17/task on the ARC-AGI 2 evaluation. OpenAI’s GPT-5 has a high score of 9.9%!!
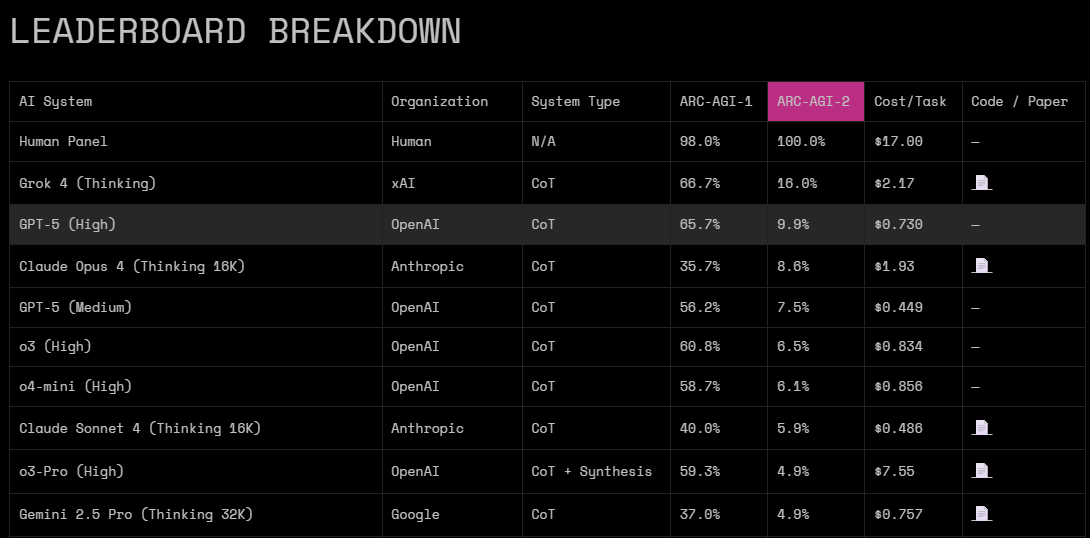
Training models to complete these tasks in similar ways that humans would, if it’s even remotely possible, inevitably requires a different architectural approach to model design. Attempts at this shift in design have not been particularly effective up to this point, but human ingenuity is without boundary so we may see ourselves approaching whatever the limit is in that space soon. While the shiniest new LLMs struggle to produce a fraction of the performance that human panels can, what fundamental changes can be ushered in to bring true reasoning and intelligence capabilities to these computers. They are currently good for many things, which makes them extremely useful tools - but they are not intelligent.
The question of the physical possibility that human-created computational machines can even approach general intelligence has been debated for decades now. The hype men claim we are on the brink of it, but I don’t think so. I can’t say I believe it’s even possible. Here are some sources on the topic:
What do you think?